航空公司客户价值分析
一、原理分析
1 、分析目标
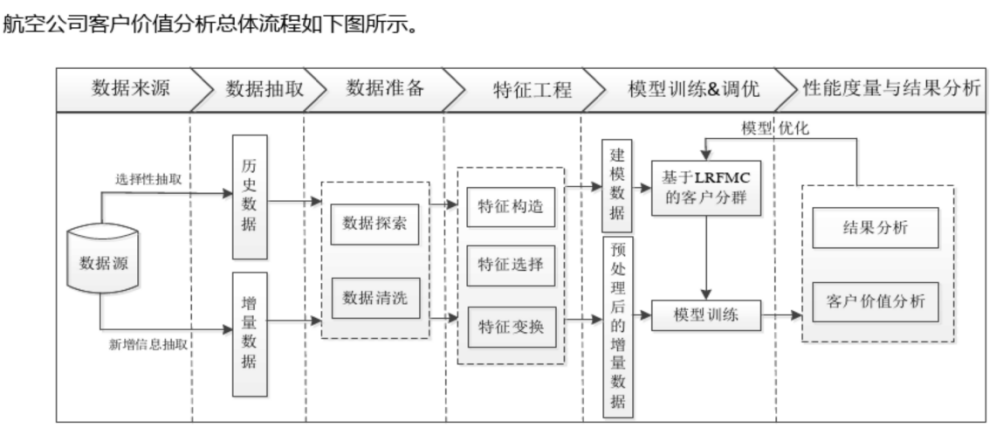
2 、基于 RFM 模型,使用 K-Means 算法进行客户分群
RFM模型是通过一个客户的近期购买行为、购买的总体频率以及花了多少钱3个维度来描述该客户价值状况的客户分类模型,这3个维度分别表示为:
最近一次消费距离现在的时间 (Recency):这个值越小对我们来说价值越大;某段时间内消费频率次数 (Frequency):这个值越大越好;某段时间内消费金额 (Monetary):这个值越大越好;
根据航空公司客户价值 LRFMC 模型,选择与 LRFMC 特征相关的 6 个特征:FFP_DATE、LOAD_TIME、FLIGHT_COUNT、avg_discount、SEG_KM_SUM、LAST_TO_END
二、 实验步骤设计(主要程序的原理)
1、数据清洗:

在数据清洗过程中,因为原始数据量大,缺失值和异常值在数据集中占比较小,所以需要对缺失值和异常值均进行删除处理,即丢弃票价为0 ,或平均折扣率为0 ,或总飞行公里数为0的记录。
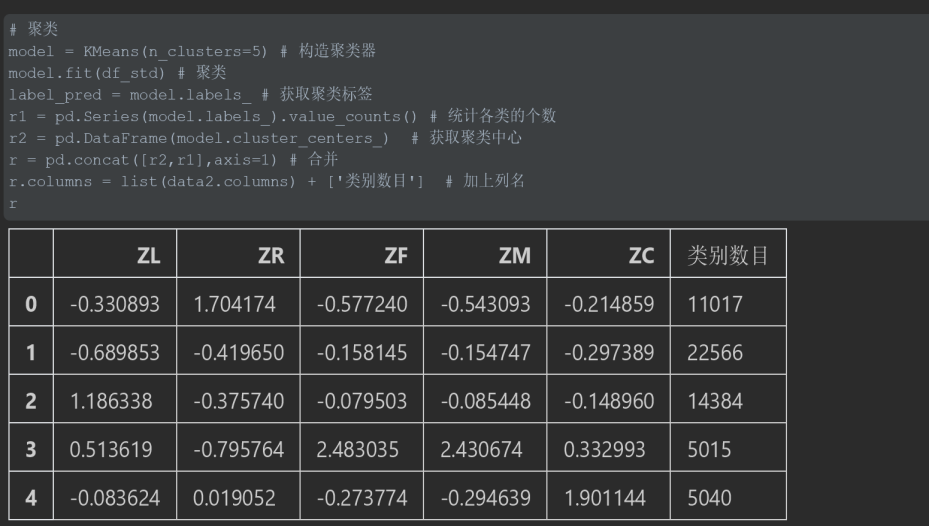
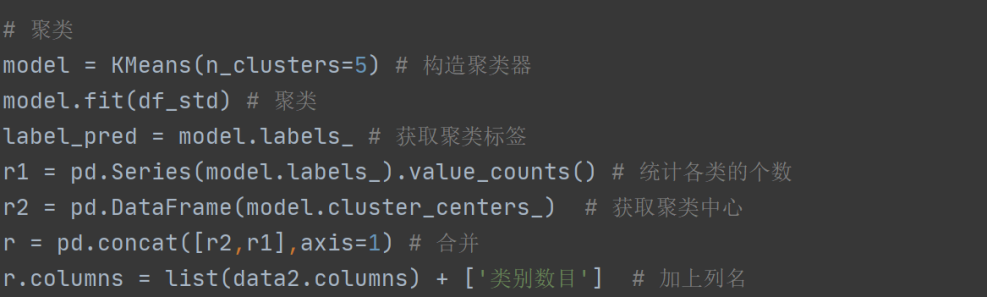
2、聚类
三、 实验结果
客户特征雷达图:
![$EPW5)XW]DZWDO9$H]S(C]M](https://pic.tmxbk39.com/images/2023/01/03/EPW5XWDZWDO9HSCM.png)
客户群1在F,M 特征最大,在R特征最小,因此可以说F,M ,R在群1是优势特征;以此类推,F,M,R在群3上是劣势特征
相关代码:
#%%
#-*-coding:utf-8-*-
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import matplotlib; matplotlib.use('TkAgg')
dataset=pd.read_csv(r'D:\Customer_Info.csv')
print(dataset)
X=dataset.iloc[:,[4,3]].values
from sklearn.cluster import KMeans
sumDs=[]
for i in range(1,11):
kmeans=KMeans(n_clusters=i)
kmeans.fit(X)
sumDs.append(kmeans.inertia_)
print(kmeans.inertia_)
plt.plot(range(1,11),sumDs)
plt.title('the Elbow method')
plt.xlabel('number of cluster k')
plt.ylabel('SSE')
plt.show()
kmenas1=KMeans(n_clusters=3,init='k-means++',max_iter=300,n_init=10,random_state=0)
y_kmeans=kmenas1.fit_predict(X)
plt.scatter(X[y_kmeans==0,0],X[y_kmeans==0,1],s=100,marker='^',c='red',label='poor')
plt.scatter(X[y_kmeans==2,0],X[y_kmeans==2,1],s=100,marker='o',c='green',label='middle')
plt.scatter(X[y_kmeans==1,0],X[y_kmeans==1,1],s=100,marker='*',c='blue',label='rich')
plt.scatter(kmenas1.cluster_centers_[:,0],kmenas1.cluster_centers_[:,1],s=250,c='yellow',label='Centroids')
plt.title('clusters of customer info')
plt.xlabel('deposit')
plt.ylabel('age')
plt.legend()
plt.show()
#%%
# 导包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn import preprocessing
import warnings
warnings.filterwarnings('ignore') # 忽略警告
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示
data = pd.read_csv('D:\air_data.csv', sep=',')
data.shape
#%%
# 删除缺失值
data = data.dropna(axis=0,how='any')
data.shape
#%%
# 删除票价为0、平均折扣率不为0、总飞行公里数大于0的数据
t1 = data['SUM_YR_1']==0
t2 = data['SUM_YR_2']==0
t3 = data['avg_discount']>0
t4 = data['SEG_KM_SUM']>0
tt = []
for f in range(len(t1)):
if t1[f] & t2[f] & t3[f] & t4[f]==True :
tt.append(f)
data = data.drop(tt,axis=0)
# 将索引重新排序
data = data.reset_index(drop = True)
data.shape
#%%
# 取出我们要分析的列数据
data1 = data[['LOAD_TIME','FFP_DATE','LAST_TO_END','FLIGHT_COUNT','SEG_KM_SUM','avg_discount']]
data1
#%%
# 会员入会时间距观测窗口结束的月数 = 观测窗口的结束时间 - 入会时间
m = (pd.to_datetime(data1['LOAD_TIME'])-pd.to_datetime(data1['FFP_DATE']))//30
data1['L']=m.dt.days
# 再取出我们最终模型需要的列数据
data2 = data1[['L','LAST_TO_END','FLIGHT_COUNT','SEG_KM_SUM','avg_discount']]
# 更换列名
data2 = data2.rename(columns={'L': 'ZL', 'LAST_TO_END': 'ZR','FLIGHT_COUNT':'ZF','SEG_KM_SUM':'ZM','avg_discount':'ZC'})
#%%
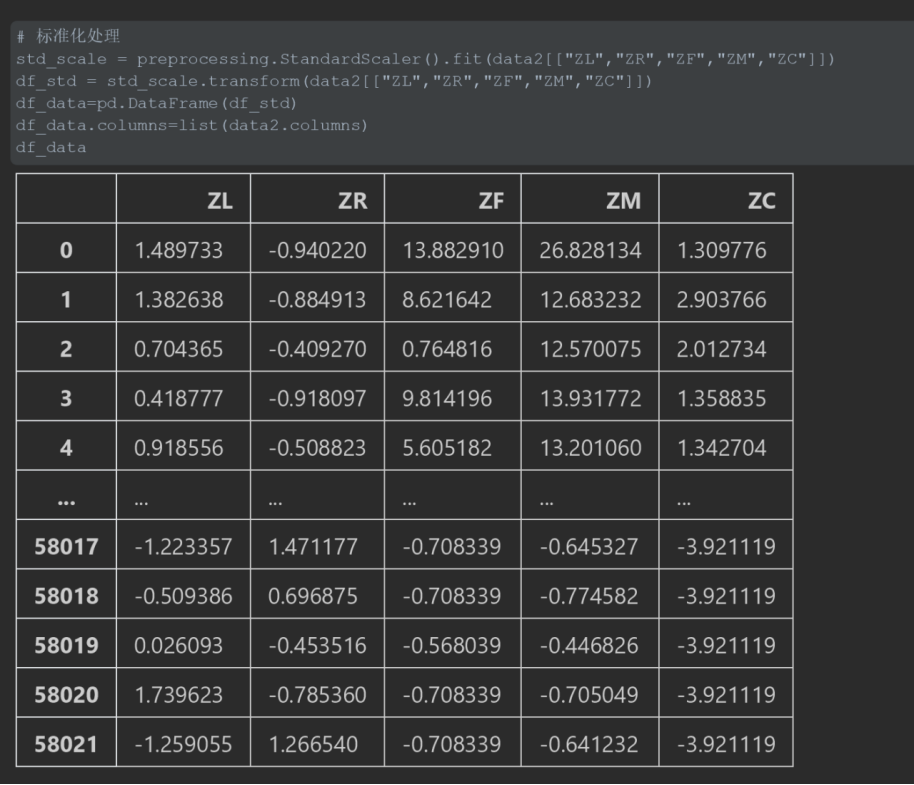
# 标准化处理
std_scale = preprocessing.StandardScaler().fit(data2[["ZL","ZR","ZF","ZM","ZC"]])
df_std = std_scale.transform(data2[["ZL","ZR","ZF","ZM","ZC"]])
df_data=pd.DataFrame(df_std)
df_data.columns=list(data2.columns)
df_data
#%%
# 聚类
model = KMeans(n_clusters=5) # 构造聚类器
model.fit(df_std) # 聚类
label_pred = model.labels_ # 获取聚类标签
r1 = pd.Series(model.labels_).value_counts() # 统计各类的个数
r2 = pd.DataFrame(model.cluster_centers_) # 获取聚类中心
r = pd.concat([r2,r1],axis=1) # 合并
r.columns = list(data2.columns) + ['类别数目'] # 加上列名
r
#%%
r3 = pd.concat([df_data,pd.Series(model.labels_,index=df_data.index)],axis=1) # 给df_data加上一列按照df_data索引,标签为值值的列
r3.columns = list(data2.columns) + ['聚类类别'] # 加列名
r3
#%%
# 根据r2绘制雷达图
labels = np.array(['ZL','ZR','ZF','ZM','ZC'])
labels = np.concatenate((labels,[labels[0]]))
N = len(r2)
angles = np.linspace(0, 2 * np.pi, N, endpoint=False)
data = pd.concat([r2,r2.loc[:,0]],axis=1)
angles = np.concatenate((angles, [angles[0]]))
fig = plt.figure(figsize=(8,8))
ax = fig.add_subplot(111, polar=True) # 参数polar, 以极坐标的形式绘制图形
# 画线
j=0
for i in range(0,5):
j=i+1
ax.plot(angles,data.loc[i,:],'o-',label="客户群"+str(j))
# 添加属性标签
ax.set_thetagrids(angles*180/np.pi,labels)
plt.title(u'客户特征雷达图')
plt.legend(loc='lower right')
plt.show()
#%%
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏